Frustrating SEO Problems
A deep dive into common and frustrating SEO problems facing webmasters and SEOs, from zero-click results to GMB spam and shrinking organic landscapes.
In the past year alone, the search industry has evolved at a pace that has never before been achieved.
With every development, update, and expansion, however, there are a new series of unique problems or challenges that every SEO or webmaster must overcome.
In this article, I have highlighted a variety of issues that have recently come under discussion or are simply common SEO issues that webmasters face on a daily basis. Including problems caused by search engines themselves, or issues created through SEO strategies.


Google showing third party product review sites for branded terms inside the knowledge panel
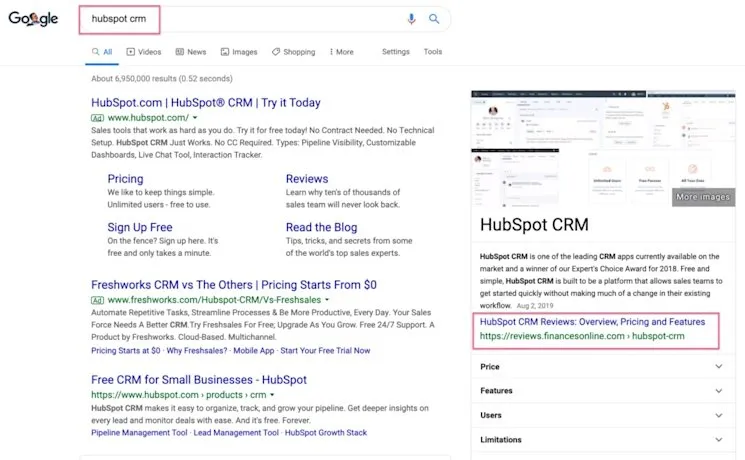
Sometimes it can be the case that Google will show users product reviews on separate sites for branded terms.
This can be especially painful when a brand happens to be paying for PPC and a knowledge panel appears from another site during a search.
It doesn’t seem to follow any patterns. As we can see, when a user searches for a branded CRM term, a knowledge panel is shown from a third-party review site, which could lead the user away from the actual site that they require.
Competitors can also appear for your brand terms if they are bidding on them in paid search.
Sites suffering from keyword cannibalisation issues
If a site creates a lot of content that caters to the same keywords, this could result in serious cannibalisation issues.
For instance, if you have supporting articles that discuss the products sold on your site, the end result could be that these pages rank higher than the actual product pages.
This can cause a series of issues, as your link hierarchy could weaken, your site traffic could be diluted, and you could lose sales.
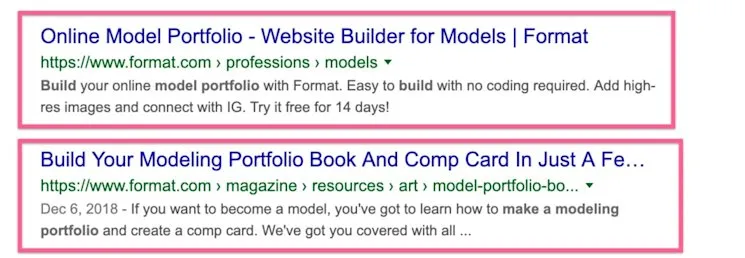
It could be also for mixed intent as Google cannot figure out the exact search intent and might be displaying similar pages for a given query.
Furthermore, Google could deindex your product page if it finds that the content is too similar to the supporting article, and for some reason, it thinks the supporting page is more important.
As you can imagine, keyword cannibalisation is a serious issue, especially for e-commerce websites, but there are (thankfully), a variety of solutions for solving keyword cannibalisation.
If you’re looking for a faster way to see your cannibalized keywords you can use Sistrix’s built-in feature.
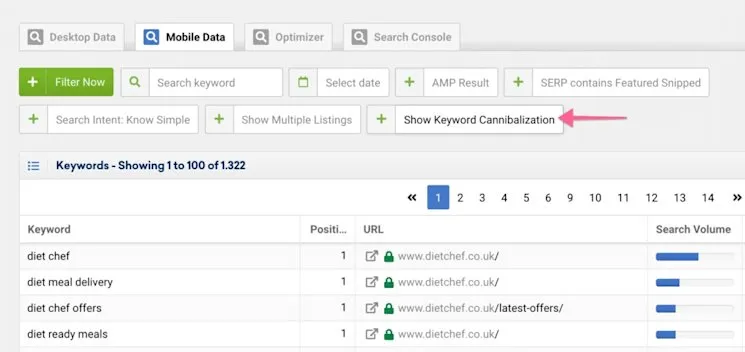
I have recently gone into great depth about solving keyword cannibalisation issues in this article for G2 Learning.
Searches offer zero-click results
It was reported in June that up to 49% of searches result in zero clicks, with organic clicks outnumbering paid clicks at a ratio of 12:1.
The research was carried out by marketing analytics company, Jumpshot, and the firm found that searches with zero clicks had risen over the last three years.
In the first quarter of 2019, the data showed that 48.96% of US searches in Google had resulted in zero clicks, representing a 12% increase from the first quarter of 2016.
Furthermore, 5.9% of searches ended with users heading to other Google-owned websites. This figure rose to 12% when a search resulted in a click.
This should be concerning to all webmasters and SEOs, especially when we consider that 12% of clicks lead to another Google affiliated company.
It is often said that Google is working its way to becoming the source of information, rather than the gateway to it.
The reality is even though the number of zero-click results is decreasing I feel it doesn’t really hurt businesses as much. Especially you have to remember most of the results could be informational.
Don’t be afraid. SEO is not dead. But, we have to remember it is becoming difficult to do SEO with the changes.
The only solution here would be to ensure that you offer accurate, compelling, and high-quality content to your users while considering technical SEO strategies, such as the implementation of structured data.
As you can now use structured data in FAQs and other elements of your site, you can help it get featured in rich results; often referred to as “position zero” by those working in digital marketing.
Shrinking SEO landscape
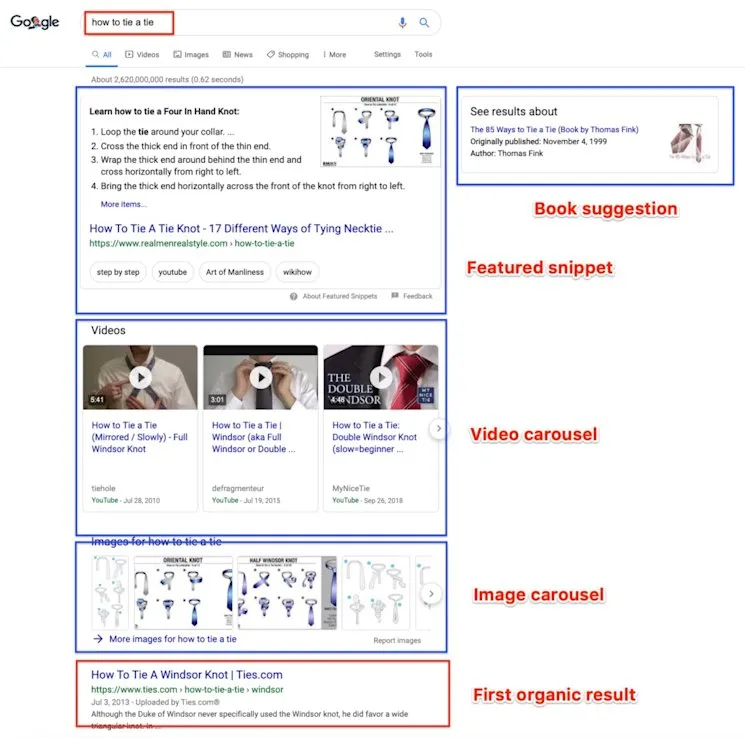
This ties in perfectly with the issue mentioned above, as when users conduct searches within Google, they are no longer faced with merely organic and paid results.
Over the past few years, Google has begun implementing a vast range of rich results that are designed to give users the information that they need as quickly as possible. These include:
- Rich answers
- Rich snippet
- Numbered list snippet
- Bulleted list snippet
- Table featured snippet
- YouTube featured snippet
- The knowledge graph
- Image carousels
- Video carousels
- Local map packs
- Top stories
For sites that don’t embrace technical SEO, or even paid search, it means that they will struggle to get the same reach or exposure that they will have attained as little as five years ago.
This is especially important as Google has also tested double and even triple featured results in the past.
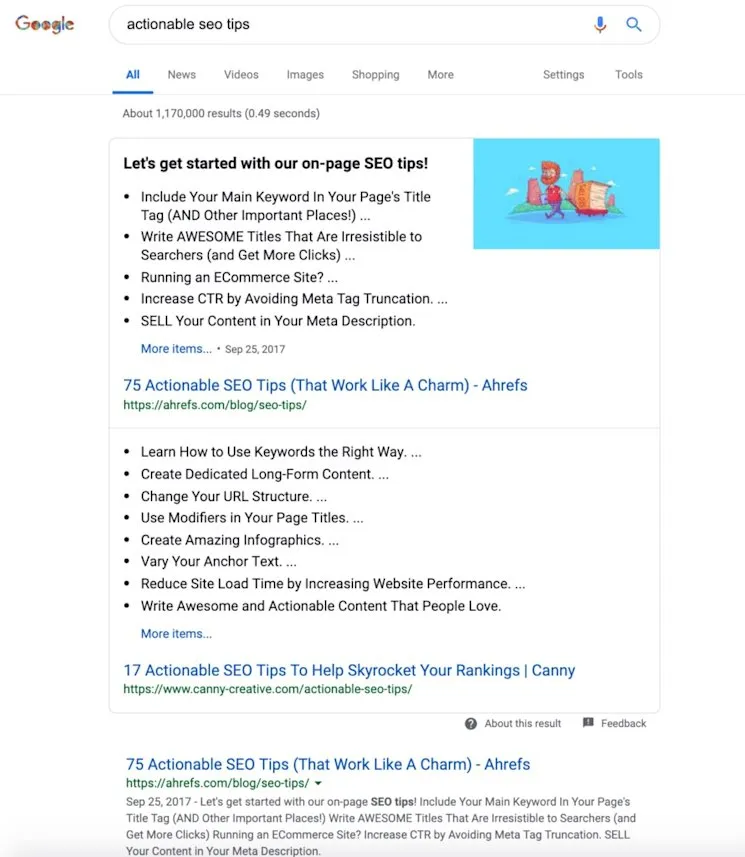
Learn more about developing your search presence in this Google Search guide.
Knowledge panels designed like featured snippets
It was reported as far back as 2018 that some knowledge panels are beginning to look more like featured snippets.
This can be quite confusing, as to the untrained eye, it might give the impression of ambiguity between informational and commercial content.
The issue here is that if the difference between the two becomes less distinct, it can create confusion for both users and webmasters over what panel is being provided to offer information and what panel is being offered to present a product or service.
Google no longer supports the noindex directive in robots.txt
From 1 September 2019 Google will no longer support the noindex directive found in robots.txt.
Instead of using the directive, this means that webmasters must use alternative techniques, including:
- Implementing noindex in robots meta tags
- Using 404 and 410 HTTP status codes
- Using password protection to hide a page
- Implementing disallow rules in robots.txt
- Use the Search Console remove URL tool
It’s worth noting that the latter option will only remove the desired URL on a temporary basis.
The Rich Results Test will replace the Structured Data Testing Tool
It was announced at Google I/O that the Rich Results Test is going to replace the Structured Data Testing Tool.
There have been several reports that there are inconsistencies between the two tools regarding the highlighting of errors and warnings within inputted markup.
As Google Search Console is in the middle of a significant revamp, this risks a period where the ability to accurately evaluate structured data becomes clouded.
There’s no doubt that inconsistencies will improve over time, but for now, it is worth double and triple-checking markup before it is implemented.
Ads in Google Assistant
It was confirmed in April that Google Assistant now provides answers to users in the form of ads.
As Google Assistant grows in popularity (it is currently installed on over a billion devices), it is increasingly lucrative to get content featured in Google Assistant.
The issue, however, is that Google seems to be increasingly monetising its results, and it means that users might not be aware that the information they are receiving is from an advertisement.
Over time it might also result in more advertisements appearing over organic answers as Google looks to increase its revenues.
Ads in Google My Business listing
It was reported recently that Google has started showing ads in Google My Business pages.
I think Google went a bit far with this one. I’m surprised there is no backlash from the SEO community and in the long run, this can hurt local businesses as bigger brands will be able to buy their way into competitors listings.
Spam in Google My Business
Google My Business is a brilliant way for local businesses to reach potential customers in their area.
In recent years, however, Google My Business has become increasingly susceptible to spam and even fraudulent activity.
A study carried out in February found that 46% of marketers often see spam in Google My Business. Furthermore, 45% of marketers said that the issue makes it harder for businesses to rank in local listings.
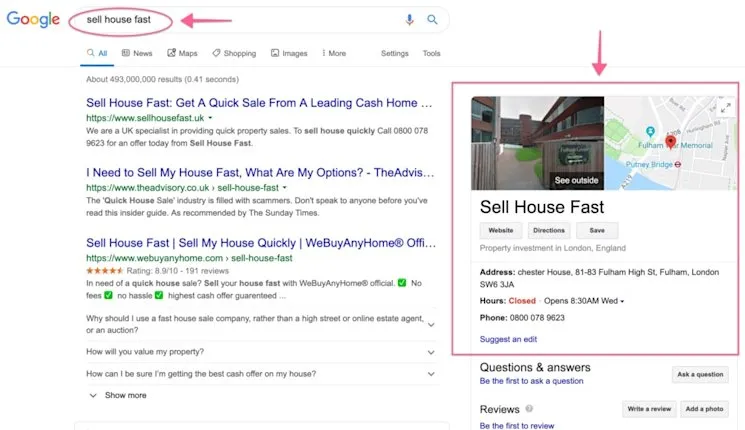
By using a trading name some companies are able to create a GMB listing for a commercial query. You can’t blame them since Google is allowing it to happen.
If you spot spam in Maps or Google My Business, however, you can take action, as Google released a Business Redressal Complaint Form, where cases are reviewed in accordance with published guidelines.
Emoji spamming in SERPs
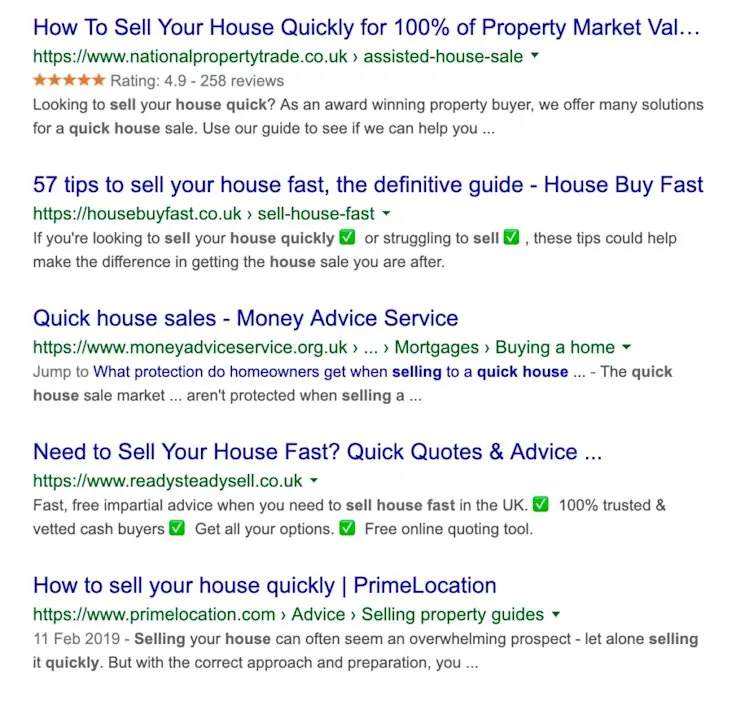
Perhaps a little more light-hearted than most kinds of spam found in search, but emojis featured within title tags and meta descriptions have always received mixed reactions from digital marketers.
Emoji spamming is not new. Back in 2015 Google killed Emojis from showing up in search results. However recent times Google has allowed emojis back into SERPs and people are already taking advantage of it.
When asked whether emojis conform to Google’s guidelines in 2016, John Mueller said that Google generally tries to filter those out from the snippets, but it is not the case that they would demote a website or flag it as web spam if it had emojis or other symbols in the description.
Emojis will be filtered out by Google, however, if they’re considered misleading, look too spammy, or are completely out of place.
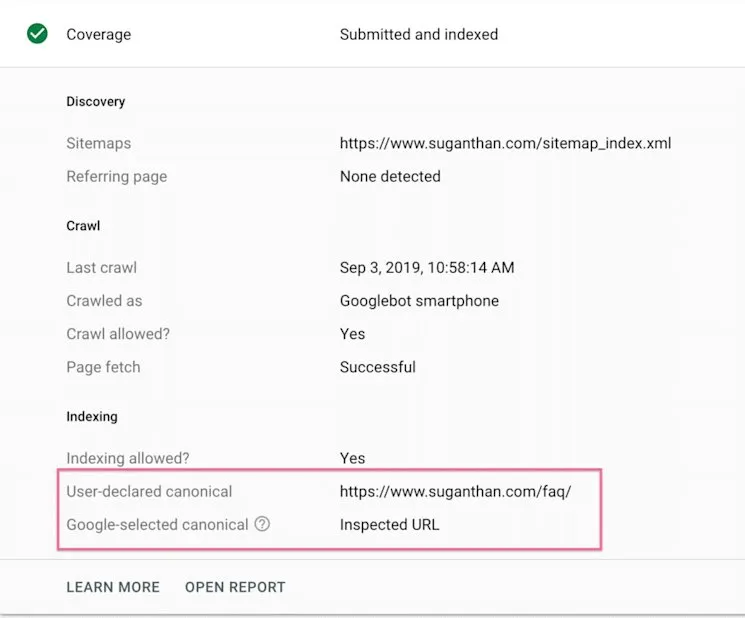
Google setting the canonicals automatically
It is often the case that a page can be found through multiple URLs. If a webmaster does not identify the best URL for Google to use in the search, it means that the search engine will try to identify the best one possible.
Although this can be very useful, it is not always the case that Google chooses the URL that you want to use.
You can check which URL Google is using by inputting the page address into the URL Inspection tool within Search Console.
There are multiple ways that you can identify canonical URLs for Google to use, including:
- Using the rel=“canonical” link tag: Map an infinite number of pages, although this can be complex on larger websites
- Using a rel=canonical HTTP header: Map an infinite number of duplicate pages, though harder with larger websites or frequently changing URLs
- Using the sitemap: Identify the canonical URL in your site’s sitemap — easy to do but not as powerful as rel=canonical
- Using a 301 redirect: Tell Googlebot that a URL is a better version than a given URL — only use when deprecating a duplicate page
- Using an AMP variant: If a variant page is an AMP page, to indicate the canonical page
Google picking its own meta description and ignoring yours

If a page contains a badly written meta description or one that is too wordy, Google can decide to ignore the one chosen by a webmaster.
Other issues can involve incorrect source code, if the Google cache is outdated, or if Google suspects there is search term manipulation.
Google can decide which snippet to show based on:
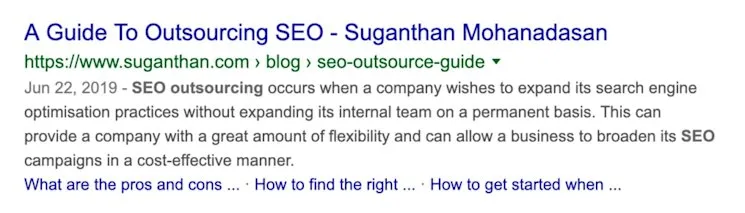
- The existing meta description in the HTML source code
- The on-page copy
- The Open Directory Project (ODP) data
Although it is hard to influence which meta description Google might choose, there are basic guidelines that you can abide by in the hopes that the search engine will use your preferred meta description.
That said, a meta description can still be affected by what search terms have been used by a user.
PDFs getting crawled and indexed by Google
It might be news to some webmasters that Google can crawl and index a site’s PDF files, but the search engine has had the ability to do this for nearly 18 years.
Having your PDFs indexed by Google is not always bad, as for example, you might want to host complex and vast instruction manuals for your products.
The problem, however, is when Google crawls and indexes PDF documents that you don’t want to be found through search engines.
For instance, if you have duplicate PDFs or ones that contain similar content or information to your webpages, you would not want them competing in the search engine results. Furthermore, you don’t want any sensitive PDF files in your server to be indexed and show up in Google search.
You can prevent PDF documents from being indexed by adding an X-Robots-Tag: noindex in the HTTP header that serves the file. Files that are already indexed will disappear from SERPs within a few weeks.
It’s worth noting that Google will also use your PDF data in featured snippets when possible.
Want my posts to show up more often on Google?
One click and Google will surface this site in your Top Stories.



Norwegian entrepreneur with 20+ years in SEO. Co-founder of Keyword Insights and Snippet Digital. Based in Dubai.